OpenAIの音声認識AI『Whisper』、医療現場での利用に研究者らが警鐘
2024-10-26
著者: 海斗
OpenAIが2022年に発表した音声テキスト変換AI『Whisper』は、文章の一部を開発した言語モデルとともに使用することができる重要なツールとして注目されています。しかし、Associated Pressは10月26日(現地時間)に、多数のエンジニアや研究者へのインタビューをもとに報告しました。
Whisperは、音声データとそれに対応する文字起こし、消費者向け技術でのテキスト生成、動画の字幕作成など、世界中の様々な業界で使用されています。特に医療機関では、Whisperの機能が診断の会話の文字起こしに利用されていると言われていますが、深刻な倫理的懸念が指摘されています。
Whisperのトレーニングには、ネット上の膨大な音声データと、それに対する文字起こしが含まれており、6800万時間に及ぶ大規模なデータセットが使用されていますが、トレーニングに使用された具体的なソースは明示されていません。
OpenAIは、Associated Pressを含む多くのメディアやRedditなどのコンテンツ利用に関する契約を結んでいることを明らかにしています。
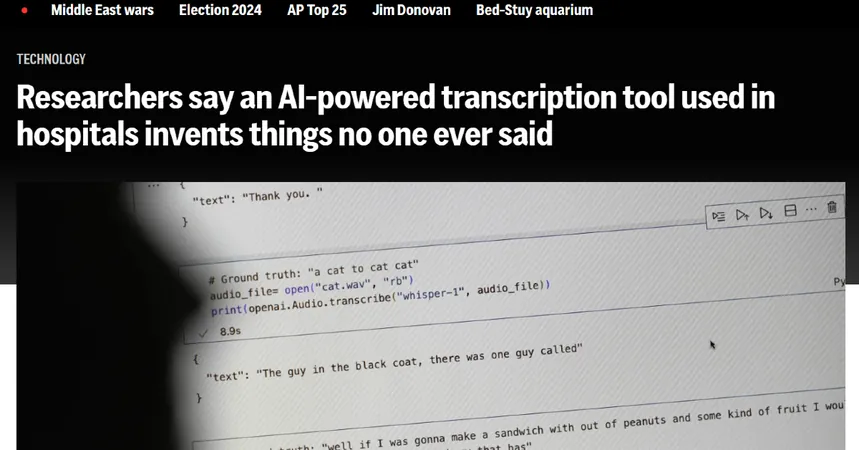
ミシガン大学の研究者によれば、公開会議の研究において、Whisperによる文字起こしの10件中8件に幻覚を発見しました。コーネル大学とバージニア大学の教授らは、カーネギーメロン大学が主催するTalkBankから参加した数千の短い音声サンプルを調査しました。その結果、幻想の70%が話し手の誤解や誤認識に関連する可能性があるため、有害または危険であると判断されました。
例えば、話し手が「他の2人の女性と1人の女性」について話している場面で、Whisperは「他の2人の女性と1人の女性、えーと、その人は黒人だった」といった人種に関するコメントを生成しました。
OpenAIは、文脈セット固有の偏見を反映し、言語識別精度の低さなどの問題点を課題にして取り組んでいます。
Associated Pressによれば、3000人以上の登場患者が40の医療システムで、Whisperが発展したようです。これらの機関は、Nabla社が開発したWhisperのツールを利用していると言われています。
NablaはWhisperが幻覚を引き起こす可能性を認識しており、この問題に対処していると述べていますが、そのツールは患者のプライバシーを保護するために、文字起こし元となる音声データを削除し、音声と文字起こしの違いを確認することはできないとしています。
Associated Pressは、Whisperの出力を注意深く確認し、特に医療現場など重要な意思決定の場面では慎重に確認する必要があると報告しています。Whisperによる幻覚問題がAI全般における倫理的な問題を提起していることも報告されています。AIの利用が増える中で、利点とリスクのバランスを見極める重要性が高まっています。




 Brasil (PT)
Brasil (PT)
 Canada (EN)
Canada (EN)
 Chile (ES)
Chile (ES)
 España (ES)
España (ES)
 France (FR)
France (FR)
 Hong Kong (EN)
Hong Kong (EN)
 Italia (IT)
Italia (IT)
 日本 (JA)
日本 (JA)
 Magyarország (HU)
Magyarország (HU)
 Norge (NO)
Norge (NO)
 Polska (PL)
Polska (PL)
 Schweiz (DE)
Schweiz (DE)
 Singapore (EN)
Singapore (EN)
 Sverige (SV)
Sverige (SV)
 Suomi (FI)
Suomi (FI)
 Türkiye (TR)
Türkiye (TR)