Revolutionizing AI Vision: How Synthetic Training Data is Changing the Game
2025-07-21
Author: John Tan
AI Vision's Breakthrough with Synthetic Data
In the competitive landscape of artificial intelligence, the ability to comprehend intricate images—such as medical diagrams and financial charts—is essential for autonomous operation in everyday situations. While proprietary systems like ChatGPT and Claude lead the charge, their mysterious training processes leave open-source models racing to catch up.
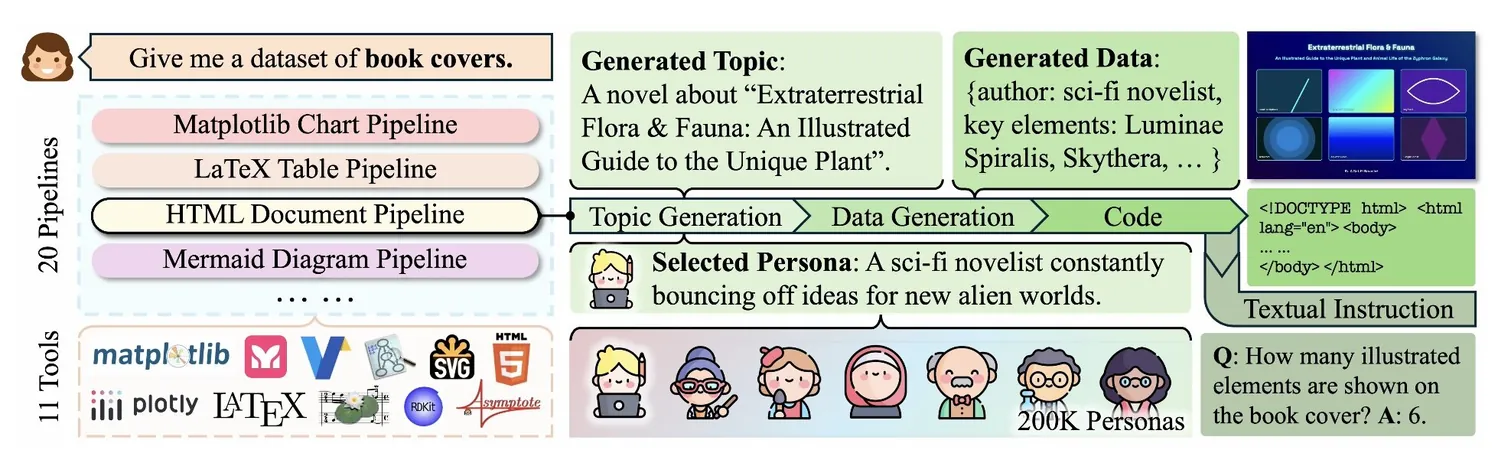
A pioneering approach has emerged from researchers at Penn Engineering and the Allen Institute for AI (Ai2), harnessing the power of synthetic training data to elevate open-source models. Their innovative tool, CoSyn (short for Code-Guided Synthesis), utilizes AI to generate scientific figures, charts, and tables, effectively allowing other AI systems to grasp complex visual information.
Transforming Learning Through Synthetic Images
In a groundbreaking paper destined for ACL 2025, CoSyn-trained models have not only caught up to but even surpassed proprietary competitors in performance. Co-author Yue Yang describes the process: "It’s akin to having a student expert in writing teach another how to draw simply through descriptive language—transferring the strength of open-source AI from text to vision."
The resultant dataset, dubbed CoSyn-400K, boasts over 400,000 synthetic images and 2.7 million text instructions across various fields including scientific charts and chemical structures. Remarkably, these models eclipsed top-tier systems like GPT-4V and Gemini 1.5 Flash in a series of seven benchmark tests.
Data Efficiency: A Champion of Results
In one standout example, researchers generated a mere 7,000 synthetic nutrition labels to train a new model for their benchmark, NutritionQA. Despite the small size, this targeted dataset outperformed models trained with millions of actual images.
"Training AI with CoSyn is incredibly data efficient," asserts Mark Yatskar, Assistant Professor in CIS and Yang’s graduate advisor. "We’re demonstrating how synthetic data can facilitate models in navigating unique real-world scenarios, such as reading nutrition labels for visually impaired individuals."
Scaling Up: Innovations in Data Generation
Creating a vast repository of varied training examples wasn't without its hurdles. To efficiently generate the needed scale, doctoral student Ajay Patel developed DataDreamer—a software library that automates the data generation process. This innovation enabled mass production of synthetic images and accompanying instructions through parallel processing.
To maintain diversity and avoid redundancy, the research team incorporated "personas"—short character profiles like "a sci-fi novelist" or "a chemistry teacher"—which influenced the AI’s responses, resulting in richer, more varied training data.
Democratizing AI Development
By building CoSyn with open-source tools, the researchers aim to level the playing field, granting widespread access to advanced vision-language training methods while sidestepping the ethical dilemmas associated with web scraping and copyrighted materials.
Chris Callison-Burch, Professor in CIS and co-advisor to the research team, emphasizes, "This is a gateway for AI to facilitate groundbreaking scientific discoveries, enabling systems that can interpret complex documents to assist everyone from students to researchers."
The Future of AI: From Understanding to Interacting
The CoSyn code and dataset are now publicly accessible, inviting collaboration from the global research community. Yang envisions a future where synthetic data not only allows AI to comprehend images but also to interact with them—acting as intelligent assistants capable of performing tasks.
"Our ultimate goal is to create AI that can engage with the world, not just describe it," Yang notes. "This is a vital step towards achieving that vision."
 Brasil (PT)
Brasil (PT)
 Canada (EN)
Canada (EN)
 Chile (ES)
Chile (ES)
 Česko (CS)
Česko (CS)
 대한민국 (KO)
대한민국 (KO)
 España (ES)
España (ES)
 France (FR)
France (FR)
 Hong Kong (EN)
Hong Kong (EN)
 Italia (IT)
Italia (IT)
 日本 (JA)
日本 (JA)
 Magyarország (HU)
Magyarország (HU)
 Norge (NO)
Norge (NO)
 Polska (PL)
Polska (PL)
 Schweiz (DE)
Schweiz (DE)
 Singapore (EN)
Singapore (EN)
 Sverige (SV)
Sverige (SV)
 Suomi (FI)
Suomi (FI)
 Türkiye (TR)
Türkiye (TR)
 الإمارات العربية المتحدة (AR)
الإمارات العربية المتحدة (AR)