Shocking New Study Questions AI's Ability to Truly Reason!
2025-06-11
Author: Ling
Are AI Models Just Pattern-Matching Machines?
In a groundbreaking study released by Apple researchers, the true reasoning capabilities of AI models like OpenAI’s o1 and o3, and Claude 3.7, are under fire. The research suggests these models merely mimic patterns from their training data when faced with novel problems, raising serious questions about what it means for AI to 'think.'
The Study that Shook the AI Community
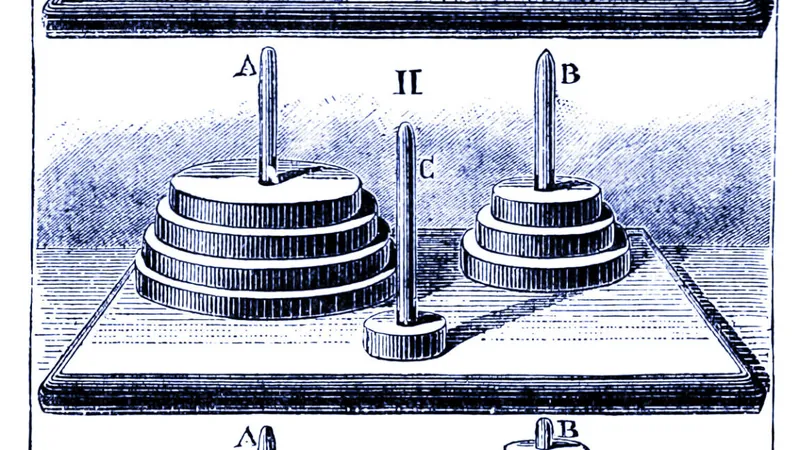
Titled "The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity," this study led by Apple’s Parshin Shojaee and Iman Mirzadeh pitted AI against classic puzzles such as the Tower of Hanoi and river crossing challenges. They scaled the difficulty from easy to extremely complex, revealing startling shortcomings in AI reasoning.
The Harsh Reality: Low Success Rates
The results were alarming. The models struggled on novel mathematical proofs, scoring under 5% overall on close to 200 attempts, with only one model managing a relatively decent 25%. The researchers highlighted a significant performance drop when faced with problems requiring in-depth systematic reasoning.
Gary Marcus Weighs In: A Devastating Critique
AI skeptic Gary Marcus didn't hold back: he described the findings as "pretty devastating" for large language models (LLMs). Marcus noted that even simple puzzles like the Tower of Hanoi, which were solvable by algorithms decades ago, left AI models floundering. He emphasized that when given clear algorithms to follow, models still could not improve—hinting at a fundamental flaw in their reasoning abilities.
The Curious Case of Reasoning Models vs. Standard Models
The study also discovered intriguing discrepancies between different types of models. For simpler tasks, standard models outperformed reasoning models due to their tendency to "overthink". However, when faced with complex challenges, both types faltered, revealing a troubling limit to their problem-solving abilities.
Counterarguments: Are we Missing the Bigger Picture?
Not everyone agrees with the grim assessment. Some researchers, like economist Kevin A. Bryan, argue that these limitations might stem from intentional constraints in training rather than a lack of understanding. He suggests that AI models might be strategically designed to focus on efficiency over exhaustive reasoning, raising questions about the interpretation of these findings.
Skepticism About Puzzle-Based Assessments
Others, including independent researcher Simon Willison, have critiqued the evaluation methods used in the study. He argues that the puzzle-based tasks may not be a fair measure of LLM capabilities and could lead to misinterpretations about their reasoning deficits.
Implications for the Future of AI Reasoning
So, what does this mean for the future? While the studies challenge the credibility of existing claims regarding AI reasoning, they also suggest that the path to more advanced reasoning abilities may require fresh approaches rather than tweaks to current models. Critics like Marcus stand firm, positing that these findings validate concerns about LLMs primarily relying on pattern-matching.
A Cautious Conclusion: AI's Place in Our World
Despite the criticism, it’s crucial to recognize the practical utility of AI models. Even if they are fundamentally pattern-matching systems, they still have significant applications, particularly in coding and content generation. As the landscape evolves, AI developers may need to adjust their narratives about reasoning capabilities to build trust and transparency with users.
The debate continues, and as AI technology progresses, the quest to uncover truly intelligent systems remains an ongoing challenge.
 Brasil (PT)
Brasil (PT)
 Canada (EN)
Canada (EN)
 Chile (ES)
Chile (ES)
 Česko (CS)
Česko (CS)
 대한민국 (KO)
대한민국 (KO)
 España (ES)
España (ES)
 France (FR)
France (FR)
 Hong Kong (EN)
Hong Kong (EN)
 Italia (IT)
Italia (IT)
 日本 (JA)
日本 (JA)
 Magyarország (HU)
Magyarország (HU)
 Norge (NO)
Norge (NO)
 Polska (PL)
Polska (PL)
 Schweiz (DE)
Schweiz (DE)
 Singapore (EN)
Singapore (EN)
 Sverige (SV)
Sverige (SV)
 Suomi (FI)
Suomi (FI)
 Türkiye (TR)
Türkiye (TR)
 الإمارات العربية المتحدة (AR)
الإمارات العربية المتحدة (AR)