AI Showdown: Which Language Model Reigns Supreme for Renal Imaging Decisions?
2025-07-04
Author: William
In the ever-evolving landscape of healthcare, the integration of artificial intelligence (AI) into clinical decision-making is not just a trend; it's a revolution. With the rise of large language models (LLMs) like ChatGPT-4.0, Google’s Gemini, and Microsoft’s Copilot, questions loom about their effectiveness in assisting medical professionals, particularly in high-stakes scenarios such as diagnosing renal colic.
The Background on Renal Colic Imaging Guidelines
Renal colic, often caused by kidney stones, leads to a significant number of visits to emergency departments (ED). In fact, reports indicate a sharp increase in these cases recently. Guidelines from the European Association of Urology recommend non-contrast-enhanced CT (NCCT) after an initial ultrasound for confirming kidney stones in patients with acute flank pain. However, confusion abounds regarding when CT scans are truly necessary and whether alternative imaging methods might suffice.
A Growing Debate in Diagnosis
Despite clinical guidelines suggesting that CT scans might not be needed for all patients, a surge in CT utilization has been noted nationally, with a mere 3% of suspected cases being managed through ultrasonography. This discrepancy raises an important question: can AI provide clarity on which imaging modality to use?
The Objective: LLMs in Action
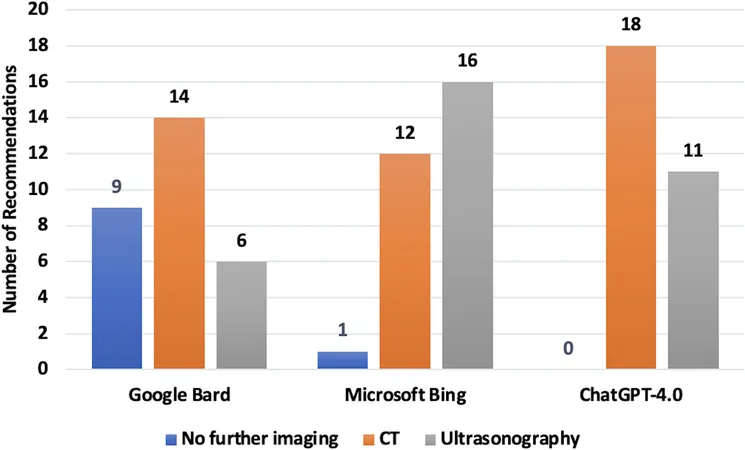
This groundbreaking study seeks to explore how effectively LLMs can determine the appropriate imaging techniques for patients facing acute flank pain. By evaluating the recommendations from ChatGPT-4.0, Gemini, and Copilot against expert consensus derived from 29 carefully crafted clinical scenarios, researchers aim to shine a light on their diagnostic capabilities.
Testing the Titans: Methodology
Between March and April 2024, each LLM was presented with identical vignettes and asked the crucial question of which imaging technique should be applied in various scenarios. Their responses were meticulously analyzed for consistency with expert consensus, gauging agreement levels across a spectrum from perfect to moderate.
Revealing Results: Gemini Takes the Lead
The findings revealed that Gemini significantly outperformed its counterparts, showcasing a remarkable agreement of 82.7% with expert evaluations. This suggested not only Gemini's ability to comprehend clinical nuances but also its potential as a reliable tool in emergency settings.
Insights and Variability in AI Responses
Discrepancies in AI recommendations may stem from the varying clinical guidelines incorporated into their training. For instance, while the study heavily leaned on the 2019 consensus report, other guidelines, like the UK's, may influence AI behavior. This opens doors to future inquiries into how LLMs process differing guidelines and adjust their outputs accordingly.
Ethical Considerations: AI and Patient Safety
As AI tools continue to shape healthcare, ethical dilemmas arise. The transparency of AI decision-making remains critical, necessitating that clinicians fully understand recommendations to maintain trust and uphold patient safety. Moreover, complying with strict data protection laws such as HIPAA in the U.S. or KVKK in Türkiye underscores the pressing need for ethical frameworks in AI deployment.
Looking Ahead: The Future of AI in Healthcare
Though the study has limitations, such as potential variability in scenarios and sample size considerations, it provides a solid foundation for future research. As LLMs like Gemini evolve, they could significantly enhance clinical decision-making in emergency healthcare, leading to improved patient outcomes.
In summary, while AI's integration into healthcare faces hurdles, the promising findings from this study could herald a new era of clinical efficiency and precision, especially in the realm of renal imaging.









 Brasil (PT)
Brasil (PT)
 Canada (EN)
Canada (EN)
 Chile (ES)
Chile (ES)
 Česko (CS)
Česko (CS)
 대한민국 (KO)
대한민국 (KO)
 España (ES)
España (ES)
 France (FR)
France (FR)
 Hong Kong (EN)
Hong Kong (EN)
 Italia (IT)
Italia (IT)
 日本 (JA)
日本 (JA)
 Magyarország (HU)
Magyarország (HU)
 Norge (NO)
Norge (NO)
 Polska (PL)
Polska (PL)
 Schweiz (DE)
Schweiz (DE)
 Singapore (EN)
Singapore (EN)
 Sverige (SV)
Sverige (SV)
 Suomi (FI)
Suomi (FI)
 Türkiye (TR)
Türkiye (TR)
 الإمارات العربية المتحدة (AR)
الإمارات العربية المتحدة (AR)